

Project information
- Project URL: Paper link
Project's Details
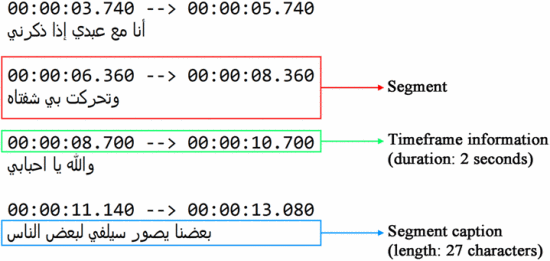
Massive Arabic Speech Corpus (MASC) is a dataset that contains 1,000 hours of speech sampled at 16 kHz and crawled from over 700 YouTube channels. The dataset is multi-regional, multi-genre, and multi-dialect intended to advance the research and development of Arabic speech technology with a special emphasis on Arabic speech recognition. In addition to MASC, a pre-trained 3-gram language model and a pre-trained automatic speech recognition model are also developed and made available to interested researchers. To enhance the language model, a new and inclusive Arabic speech corpus is required, and thus, a dataset of 12 M unique Arabic words, originally crawled from Twitter, is also created and released. Evaluating our newly introduced evaluation sets, the best word error rate achieved by the speech recognition model is 19.8% for the clean development set and 21.8% for the clean test set. The papers has been published on 2022 IEEE Spoken Language Technology Workshop (SLT)